
日本企業が取り組むべきデジタルトランスフォーメーション(以下 DX)は、もはや助走期間を過ぎました。
2025年の崖を乗り越えデジタル競争の勝者となるためには、よりスピーディに、よりスマートに、企業活動を発展させていく必要があります。
経営とITが不可分である今日、その原動力となるのは企業情報システムです。
なかでも基幹システムは、より多くの処理をこなすだけでなく、より高いパフォーマンスで処理する能力が今まで以上に求められています。
さらに、取るべき戦略を多角的な視点で分析しすばやく意思決定を行っていくために、AIを日常的に活用していく必要があります。
また、ランサムウェアを始め、企業にとってシステムへの脅威は高まる一方で、従来以上にセキュリティ強化を図ることは不可欠です。セキュリティ強化という観点では、データのみならずハードウェアやOSも視野に入れなくてはなりません。
加えて近年は、産業界全体で脱炭素社会の実現をめざしており、企業の取り組みの進度が取引先選別のポイントにもなろうとしています。
企業が直面するこうした様々な課題を解決するために進化したのが、IBM Powerの最新版「IBM Power10」です。
当コラムでは、ハイエンドエンタープライズシステムE1080を基準に、POWER9からパワーアップした機能の数々と、おすすめの活用シーンを紹介します。
Index
- POWER9から大きくステップアップしたPower10
- 今のビジネスにすぐ貢献 -IBM Power10の適用シーン-
- POWER9との違いを知りぬいたエヌアイシー・パートナーズにご相談を
- この記事に関するお問い合わせ
- 関連情報
POWER9から大きくステップアップしたPower10
IBMは、プロセッサーからメモリーインターフェース、筐体間通信までを一貫して設計する唯一のベンダーです。
そのため、ビジネス最前線での利用ニーズを見極めながら、あらゆるコンポーネントを相互に最適化させて作り上げることが可能です。
これまでもその取り組みは行われてきましたが、IBM Power10においてその利点が最大限に発揮されたといえそうです。
システム全体で目指したパフォーマンスの向上
Power10プロセッサーは、7nm (ナノ・メートル) にて製造されています。POWER9の14nmからプロセスルールを半分にすることにより、最大15コアの搭載が実現しました。
トランジスタ密度がさらに向上したことでコアパフォーマンスが向上し、より多くのワークロードへの対応が可能になります。
実際 IBMによる自社製品の比較検証で、コアパフォーマンスはE980と比較して20~30%増加※1、E880Cとの比較では55~80%増加※1しているといいます。
これは、こうした既存機種を複数ノードで利用していたワークロードがあれば、E1080へ統合可能であることを意味します。
また、コアライセンス体系を持つソフトウェア利用ではライセンス費用の見直しにもなります。
メモリーでは、新しいOpen Memory Interface (以下 OMI) が導入されました。
チップあたり16チャネル搭載が可能となった結果、最大1TB/sの帯域幅を実現。POWER9の230GB/sに比して、4倍以上の性能向上となっています。
また、PowerAXONにより、筐体間でのメモリーのシェア (クラスタリング) が可能になり、メモリー使用の最適化が行えます。
一方インタフェースにおいては、POWER9はPCIe Gen4でしたが、PCIe Gen5にアップデートされたことで、従来比1.8倍※1の帯域幅を提供します。
このように、IBM Power10は、CPU単体性能の向上だけでなく、チップからメモリー、I/Oデバイス、ノード間に至るまでシステム全体で広帯域・低遅延のデータ通信を実現し、コアを中心に行うデータ連携のボトルネックが様々な点で解消されています。
※1. IBMによる自社製品調べ (2021年9月)
ハードウェアレベルからのセキュリティ強化
企業の重要な資産である情報システムを守り抜くために「セキュリティはあらゆる角度から考慮すべきだ」とIBMは考えています。
IBM Power10においても、ハードウェアであるプラットフォームからアプリケーションレベルでのワークロードまで、Power10セキュリティエコシステムと称された様々なセキュリティ対策が施されています。
特に目を引くハードウェアのセキュリティ対策では、メモリー暗号化機能が強化されました。
チップ上のメモリーコントローラ内に搭載された暗号化エンジンにより、OSやアプリケーションの種類に関わらず、透過的かつ容易にデータを暗号化できます。
その能力も、POWER9に比べ4倍※1 のAES暗号化エンジンをすべてのCPUコアに搭載しているため、約40%以上の高速化がされており、アプリケーションパフォーマンスへの影響を最小限に抑制可能です。
また、このシステムは来たるべき時代に備え、量子コンピュータにも耐えうる暗号化や、暗号化されたデータを復号化することなく演算を行えるデザインであることも大きな特長です。
つまり、IBM Power10は、ハードウェアレベルから強力なセキュリティ対策を施すことで保護とパフォーマンスを両立しており、新しい脅威にも対応できるといえます。
※1. IBMによる自社製品調べ (2021年9月)
IBM Power10だけでもAI活用が可能に
ますます本格化するであろうAI活用のために、Power10プロセッサー上で高速な推論環境が構築できるようになりました。
それが、Matrix-Multiply Assist (以下 MMA) で、機械学習、ディープラーニングなどのアルゴリズムを効率的に実行するための行列演算エンジンです。POWER9に比べて最大20倍※1のAI推論処理性能を有しています。
また、機械学習やディープラーニングで作ったモデルを共通のフォーマット、ランタイムで実行できるようにする、Open Neural Network Exchange (以下 ONNX) をサポートしています。
これをハブとして活用することで、機械学習やディープラーニングの学習にどのフレームワークを利用しても同じフォーマットで実行・推論することが可能です。
このように、IBM Power10では、CPUだけでもAIの推論が実行でき、かつ、ソフトウェアを含めよりスコ―プの大きなエコシステムの構築を支援することで企業のAI活用を促進します。
※1. IBMによる自社製品調べ (2021年9月)
可用性、信頼性、保守性をさらにパワーアップ
1年365日停止することの許されないミッションクリティカルなビジネスを支えるため、IBM Power10は、さらに信頼性、可用性を高めています。
リトライ/リカバリーと自己修復のための機能を備えたプロセッサーや、OMIに接続する先進的なメモリーDIMMの搭載がまさにそのためのもの。
さらに、IBM Power10のDIMMは、業界標準のDIMMと比較してメモリーの信頼性と可用性が2倍向上※2しています。
また、新しいノンアクティブ32Gb SMPケーブル採用により、信頼性が向上したのみならず時間領域反射率測定 (TDR) による障害分離が可能になり、保守性も上がりました。
加えてバックプレーン内の配線も不要になり、バスのパフォーマンス向上に寄与しています。
※2. ITIC 2020 Global Server Hardware, Server OS Reliability Report (2020年4月) に基づく
脱炭素社会実現に向けたエネルギーの高効率化
エネルギー効率の向上という点も、IBM Powerは30年以上にわたり注力を続けてきました。
今回7nmを実現したPower10プロセッサーは、POWER9に比べて約3倍のエネルギー効率を実現しています。
これは高集積とリソースの効率的な活用が可能になるということで、同じ規模のワークロードであればより少ないインフラで処理が行えるということです。
消費電力の削減、ひいてはCO2排出量の削減につながることで、単に企業内でTCO削減が実現するというだけでなく脱炭素社会実現に向けた取り組みにもなります。
サステナブル時代に生きる企業にとって、エネルギーを意識した活動はもはや使命といえます。
今のビジネスにすぐ貢献 -IBM Power10の適用シーン-
より少ないインフラで稼働してコスト削減
最大15コアという高集積なPower10プロセッサーを有効活用することにより、様々な業務の “コンパクト化” が実現できます。
まず、アプリケーション稼働にリソースが必要な場合、多くのコアで筐体数を減らせます。
例えば、POWER E980 2ノードで稼働していたシステムは Power E1080 1ノードに集約できる可能性があり、そうなれば約33%の消費電力が削減可能※1です。
次に、OracleやSAP HANAなど、アプリケーションのライセンス課金体系がCPU単位である場合、コアの集積度向上とコアあたりの性能向上により、TCO削減の効果が期待できます。
またIBMは、IBM Power10がAIX、IBM i、Linix上で稼働する数千ものISVアプリケーションに対応することを表明しています。
これにより、例えば、RedHat OpenShift対応の様々な業務をこの上で動かすことも可能です。
※1. IBMによる自社製品調べ (2021年9月)
データがある場所でAIを実行
“Train Anywhere, Deploy here”。これは、IBM Power10におけるAIコンセプトです。
その意味は、”学習はどの場所でも、デプロイは「IBM Power10」で” というものです。
AIのモデルというのは、一度作れば終わりではありません。変化する社会情勢や事業環境に合わせて日々アップデートする必要があります。
そこで最適なのが、Power10プロセッサーに搭載されたMMAの行列演算エンジンです。
これを用いれば、作成したモデルを基幹業務が稼働しているプラットフォームのすぐ横で動かすことができます。
例えば、同じAIXで稼働している基幹業務のすぐ隣にLinux区画を作り、そこでAIモデルを実行するといった具合です。
外部からやってくるトランザクションデータを取り込むにも同じ筐体で稼働するため、データ転送のオーバーヘッドが小さく管理するプラットフォームも小さく抑えられます (図1)。
また、高パフォーマンスのIBM Power10を用いることにより、システム全体としてのSLA達成も容易になります。
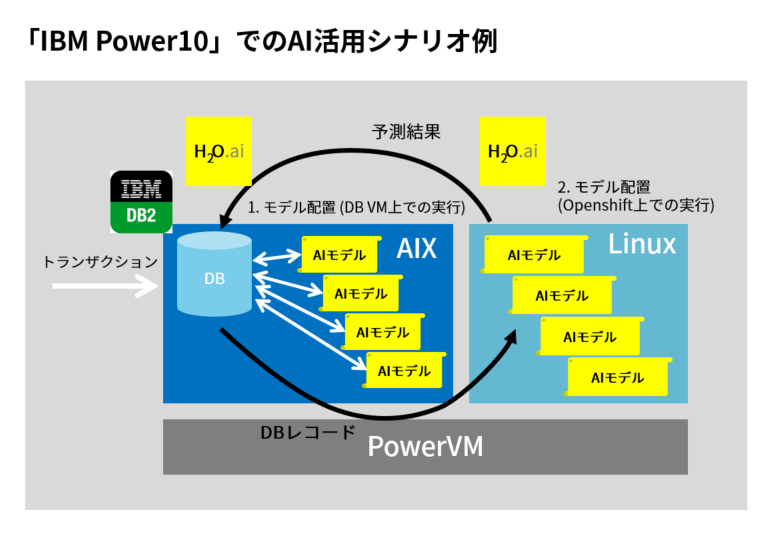
図1. IBM Power10でのAI活用シナリオ例
“摩擦レス” にハイブリッドクラウドを動的に拡張
クラウドへのリフト&シフトが進行している今日ですが、「従来のITとうまく統合できない」と悩んでいる企業が多いのも事実です。
その解決策としてIBM Power10では、DynamicCapacityという機能が提供されています。
これは、コアやメモリーといったサーバーリソースを同じモデルのすべてのサーバー同士 (プール) で共有できるというもの。
また、プール内の総起動分を超過して使用した分は事前購入した従量制容量のクラウドリソースで増強できます (図2)。
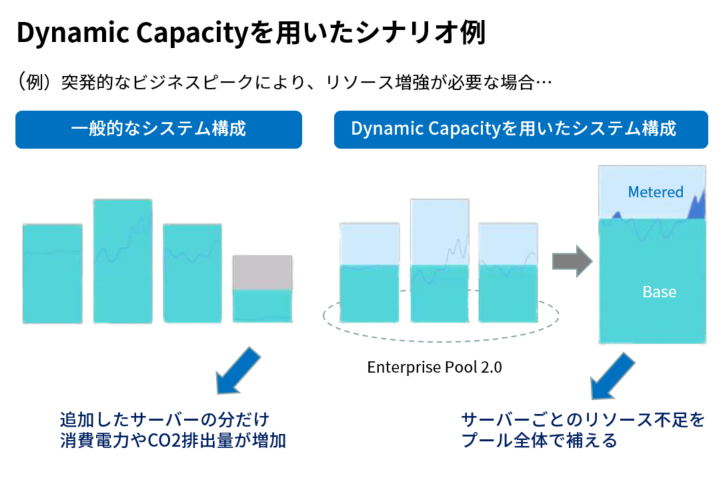
図2. IBM Power10のDynamic Capacity
そのため、企業はサーバーごとのリソース不足という問題から解放されるだけでなく、バースト的に発生したビジネスピークにいつでも対応可能になります。
また、これをリフト&シフトの一環とし、そのままクラウド上で業務を続けることもできます。
つまり、このシステムは、アプリケーションが実行されている環境がオンプレミスに限られていないということです。
クラウドへも “摩擦レス” に移行でき、そこでも同様のスケーラビリティ、パフォーマンスが得られるということは、大きな差別化ポイントといえるでしょう。
POWER9との違いを知りぬいたエヌアイシー・パートナーズにご相談を
こうして見てくると、IBM Power10は、様々な面でブレークスルーを果たしています。
サーバー全体、また、クラウドを含めた情報システム全体のエコシステムという観点で、大きな性能向上、セキュリティ強化、機能追加を果たしたことがよくわかります。
まさに、ハードウェアからOS、ソフトウェア、クラウドまですべてを手がける、IBMならではの価値提案です。
「新しい分野にチャレンジしたい」
「迅速な意思決定のためにシステムパフォーマンスを上げたい」
「凶悪化の一途をたどるサイバー攻撃からシステムを守りたい」
「サステナブル対応が喫緊の課題だ」
といったご要望やお悩みを抱えるエンドユーザー企業のご担当者の方は、IBM Power Systemsに長く携わり、ローンチ以前からIBM Power10に注目し、POWER9との違いも知りぬいたエヌアイシー・パートナーズに、ぜひ、ご相談ください。
この記事に関するお問い合わせ
エヌアイシー・パートナーズ株式会社
企画本部 事業企画部
この記事に関するお問い合せは以下のボタンよりお願いいたします。
関連情報
- 【10分で早わかり】インタビュー記事「Power10の真の価値とは」(インタビュー)
– 日本IBM Powerテクニカル・セールス ITスペシャリスト の釘井 睦和 氏に「Power10の真の価値」についてお話を伺いました!
【外部サイト】(IBMサイト)